
NB! If you retrieve large amounts of information from ElasticSearch, the server may crash.
Raw data
At first, install Curl with the command “sudo apt-get install curl“. So, we needed to know which tables the ElasticSearch index has shared the data with, I got this information with Curl with the command “curl localhost:9200/_cat/indices?v | tee elasticdatabases.txt“, this command is to retrieve data directly from ElasticSearch’s port 9200 to a text file. Below is a small portion of the elasticdatabases.txt file:
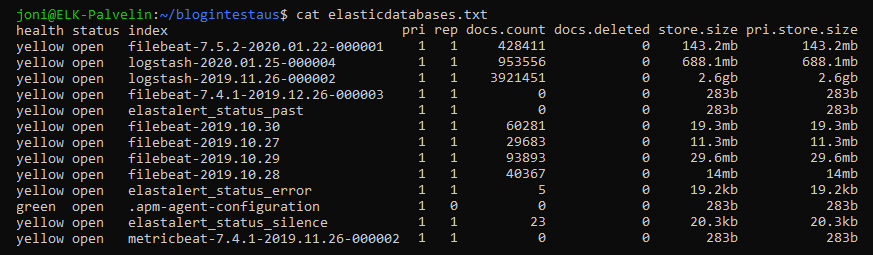
Now that the index names are known, we can now dump the maximum amount of data ElasticSearch provides in a single request, that is, 10,000 logs to the text data field using Curl with the command “curl -s localhost:9200/filebeat-2019.10.27/_search?size=10000 | tee filebeat-2019.10.27.txt“, this command is to requested the first 10,000 logs from filebeat-2019.10.27 and pipe them into a text file with tee function.
Text processing
The information we collect in “filebeat-2019.10.27.txt” is now in json format, but all 10,000 logs are on the first line of the file and hard to read for human.
If you do not want to change filebeat-2019.10.27.txt text format, the log information can now be piped to the desired data format Jquery, which is easier to read with the command “cat filebeat-2019.10.27.txt | jq“.

Or if you want to make a completely new text file that is easy to read it can be done mjson.tool python module using the command “cat filebeat-2019.10.27.txt | python -mjson.tool | tee filebeat-2019.10.27.json“, this command will first put the data in json format and at the same time put the files in a text file with tee function.
Over 10,000 logs from ElasticSearch
Culr was unable to retrieve more than 10,000 logs at a time, but a Github user Taskrabbit, had done a “Elasticsearch dump” program on Github to dump ElasticSearch databases. I downloaded ElasticSearch-dump software first by downloading the npm package manager with “sudo apt-get install npm” and I downloaded Elasticsearch-dump software from the npm package manager with “npm install elasticdump -g“. With the command below, I retrieved all 29,683 logs from the filebeat-2019.10.27 database.
elasticdump \ --input=http://localhost:9200/filebeat-2019.10.27.txt \ --output=testi.json \ --type=data
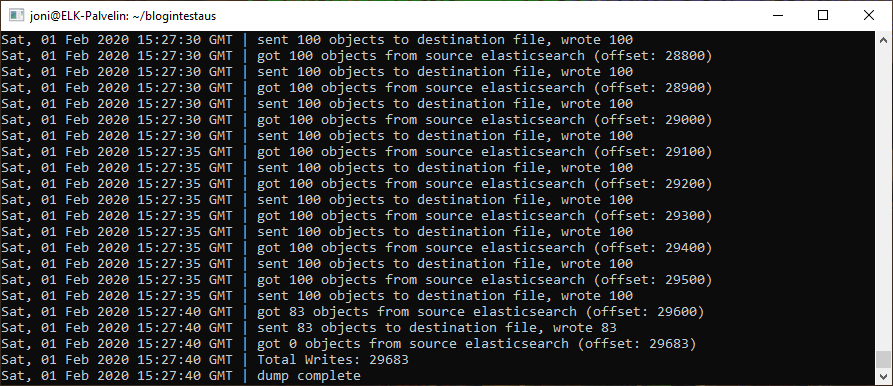
The Elasticsearch-dump script worked fine and created a file containing all 29,683-log information.
Test data for HelloWorld
The purpose of test data is to be as easy to use as possible, so we decided to use both successful and unsuccessful SSH attempts as the test data. The purpose of TensorFlow would be to notice if there are any anomalies in the data, such as logging in from China or user Joni logging in at midnight. So, TensorFlow should detect state of emergency in system. For the test data of SSH we selected time, place, user and login.
Information search from Kibana

I started by logging into the Kibana’s graphical user interface and opening the Discover tab and typed in search bar “event.action: ssh_login”, this will look up all SSH logs in ElasticSearch’s databases.
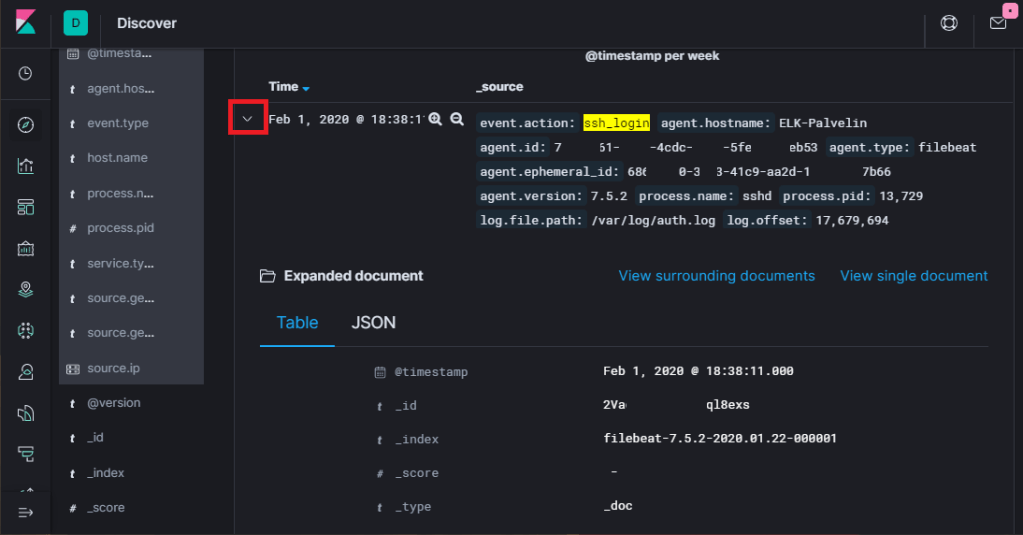
I chose a log and pressed the red arrow in the picture to get more precise details open.
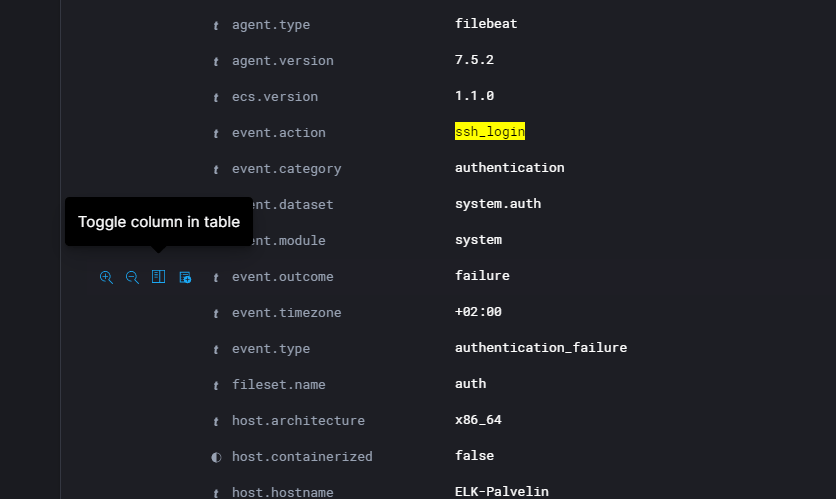
Eligible data is then selected to be filter in CSV file to file:
- Time: @timestamp
- User name: user.name
- Country: source.geo.country_iso_code
- Succeeed or not: event.outcome
I added a filter to this information with the “Toggle column in table” button shown in the picture.
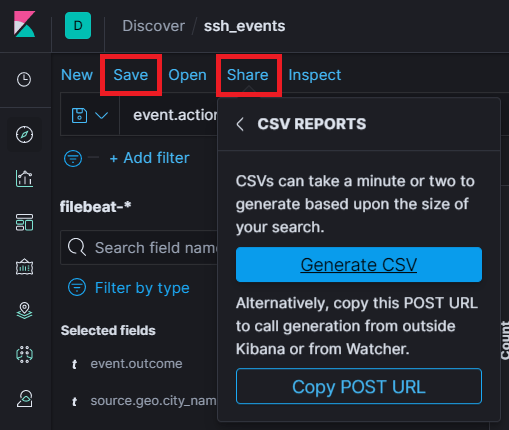
Before a CSV file can be generated, the Filters must be saved with the “Save”, “Share” and “Generate CSV” button marked in the image.
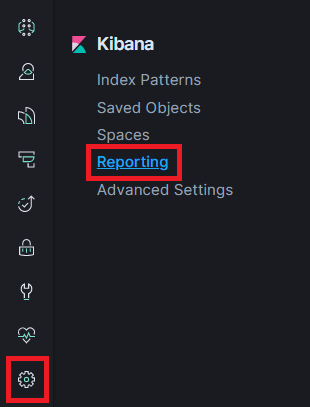
Generated CSV files can be found in the Kibana settings and “Reporting” as shown.
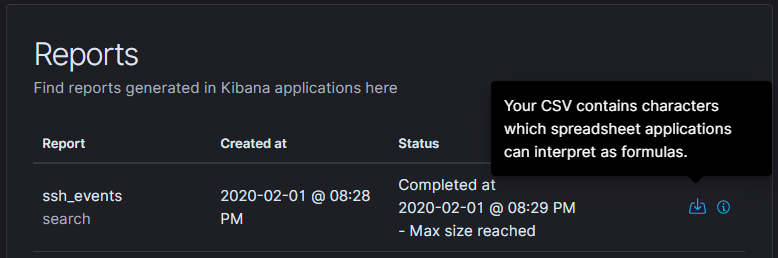
The CSV file is downloaded by pressing the download button. A raw version of this CSV file can be found on Github: https://github.com/Dunttus/AI-Project/tree/master/datasets/ssh_login
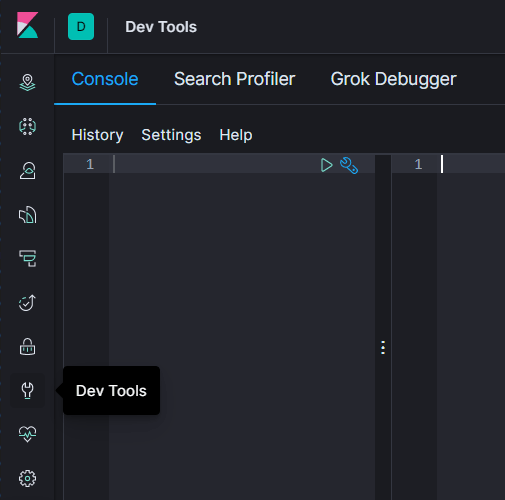
Removing data from ELK-Stack
To delete indexed databases from Elasticsearch, just open Dev Tools Console mode as shown in picture below.
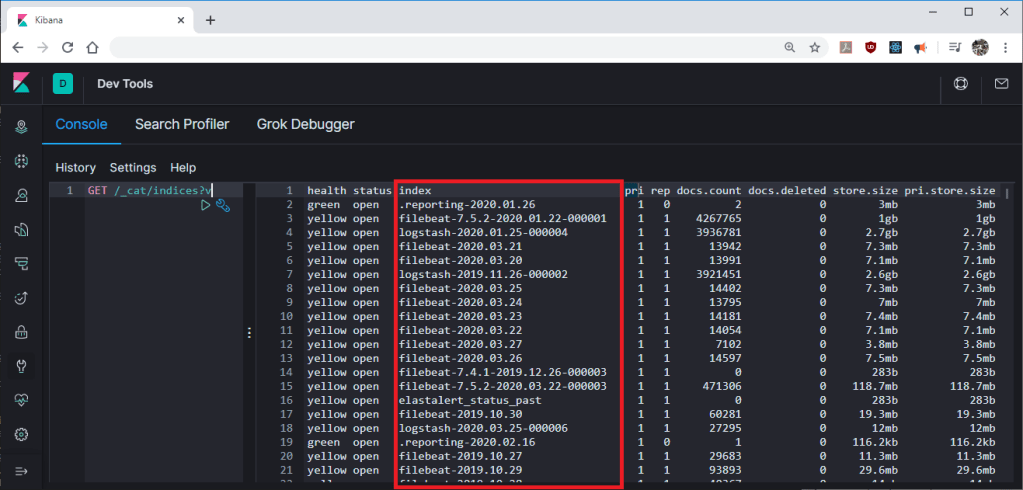
All index files can be listed with command “GET /_cat/indices?v“, just take note of index names since you will need them to deletion.
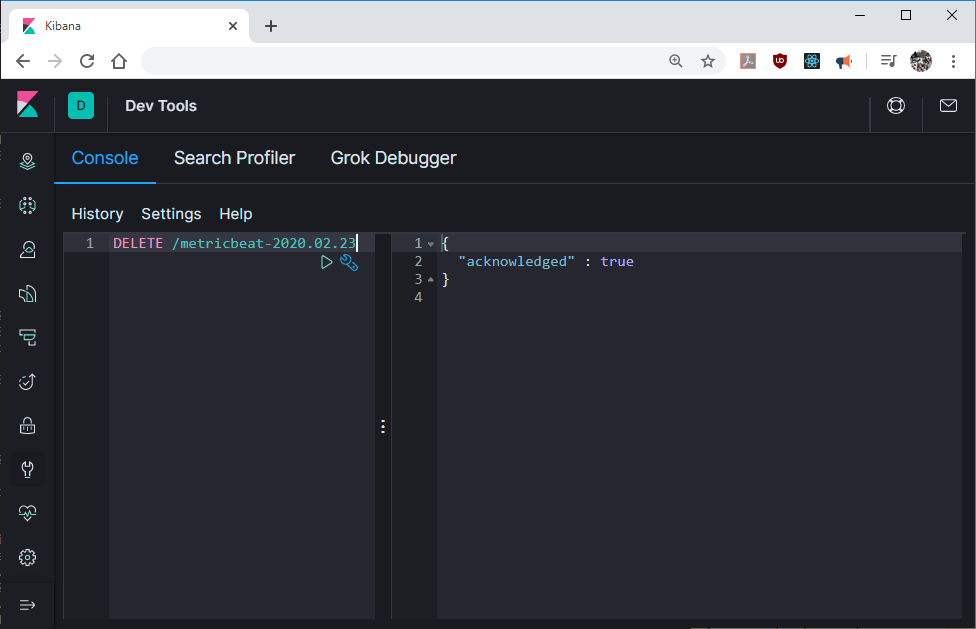
Deletion of indexed database is done with command “DELETE /indexname” which will tell you if index is deleted.
I tried to delete nonexistent index and it gave me give you error “index_not_found_exception”.

