
I’ve been using Arch Linux for years as my main working platform, and to my surprise, rsyslog was not included in the official repositories. It can be found from AUR (Arch User Repository) of course. We talked about Linux logging solutions and the various text files you can redirect the logs into with the traditional syslog solution and it’s remote cousin, rsyslog. And then we talked about systemd-journald.
Regardless what you think about systemd, most Linux distros have it as their service manager. systemd-journald is a tool for logging, and it certainly relates to this project. After all, this logging tool exists already in virtually any Linux installation, so why not use it? I searched the Internet a bit, and decided to dig a bit deeper what it actually can do.
An ye-old blog post from Lennart Poettering turns up. Plaintext logfiles have apparently been history for a while, and systemd-journald does a whole lot of more besides compressing than the traditional syslog while supporting the syslog format. We need good preprocessed data for this project, and what I know of the ELK-stack now, is that the logstash -utility is meant to process and format log entries into a database-compatible formats for further processing.
systemd-Journald as Logstash replacement?
It turns out that systemd-journald can generate JSON output besides of other processing and categorizing capabilities! It can filter by process, user id, timestamps or combine filters among. Then along with compressed data format, additional metadata is being collected as well, SELinux context for example. We have a centralized logging solution already in place on every Linux with quite a lot of capabilities in terms of sorting the data. There are remote logging capabilities aswell, but this is enough for now.
Just as an example, here is a command that shows all the metadata from last boot on my ELK-server:
$ sudo journalctl -b -o json-pretty
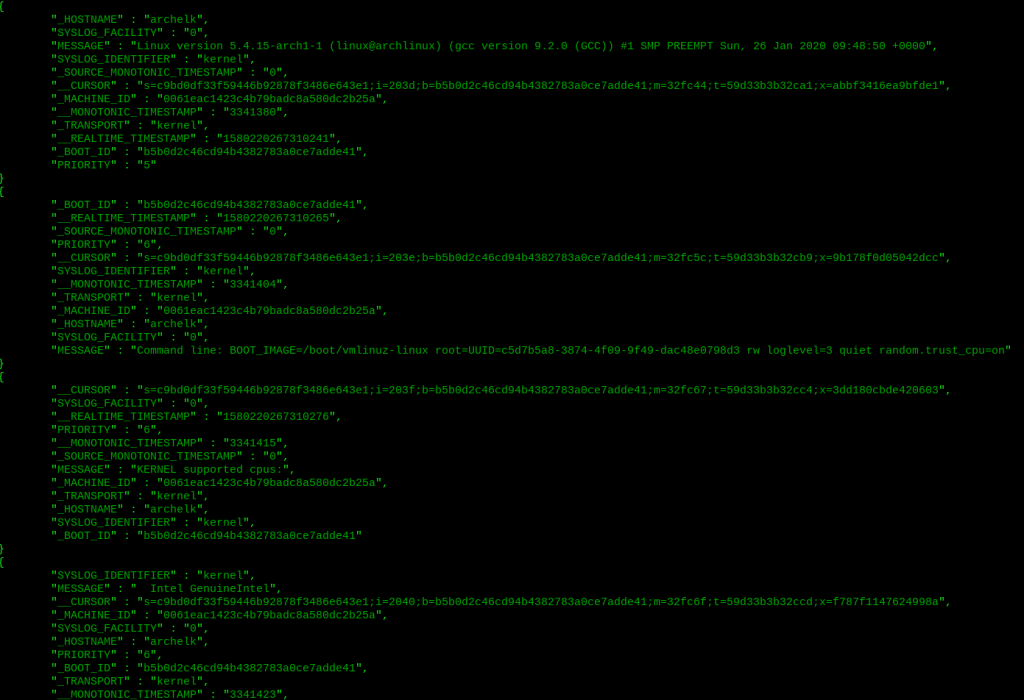
I’m going to experiment with this a bit. I can probably move the journalctl’s json output straight into elasticsearch database with curl 😉 On top, there is systemd-journald-remote… wonder what the transporting mechanism is like…
Some sources:
https://www.loggly.com/ultimate-guide/linux-logging-with-systemd/
http://0pointer.de/blog/projects/journalctl.html
-Tuomo Kuure (tqre)
PS.
So you noticed that random.trust_cpu=on kernel command:
Virtual machines have naturally low entropy, and SSH daemon and other services that require cryptographically strong random numbers might take considerably longer to start. Some modern CPU’s have a built-in random number generator, which can be used to build up entropy in boot time.
Detailed explanation of the process:
https://askubuntu.com/questions/1070433/will-ubuntu-enable-random-trust-cpu-in-the-kernel-and-what-would-be-the-effect
Also Debian wiki speaks about of this, and it seems that the newest Linux kernels (5.4 and up) have new mechanisms to provide entropy:
https://wiki.debian.org/BoottimeEntropyStarvation
