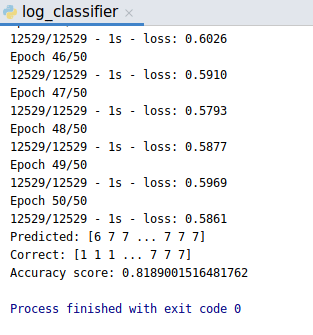
We had an eye-opening meeting earlier this week, and I started to get confident we can make our first defined milestone ready by next week. But it turned out to be closer! What we have, is a rough machine learning model that can determine log severity level from the message body only.
Parser Panda – training data
I had 3 large log files, and wanted to create a small example dataset for testing purposes. Initially, the data was not too well distributed among the levels, so I wrote some code to even it out.
Initial situation - total distribution by log level: 1: 9 2: 574 3: 602 4: 829751 5: 148710 6: 590698 7: 6317
Parser-Panda reads all the 3 log files, and takes maximum of 1000 random entries from each log level and file. It does everything as panda dataframes. As pandas do. Right? Well, it gives it back as a json file. Here is the output from the program:
Generated dataframe value counts: 6.0 3000 5.0 3000 4.0 3000 7.0 2344 3.0 602 2.0 572 1.0 9
This is inside a 1.8M json file, with only the essentials needed: loglevel and the message. Note that everytime PP does it’s thing, the file ends up being different regarding the parts that are overpopulated.
Natural language processing – word tokenizer
The messages have to be converted into numeric format for the ML algorithms to understand them. I found an article which covers the NLP basics well. A word is encoded to a number, but this is not cryptography…
The words-and-sentences-into-numbers -part affects greatly to the outcome, and there are many possibilities here. On the prototype, Keras -library tokenizer is used. The tokenizer gives a sequence of numbers as it’s output, and this is essentially the feature vector for the neural network. In other words, the input layer of the neural network consists of a number-coded sequence of the log message. What I’m trying to explain is here on the left side of the picture.
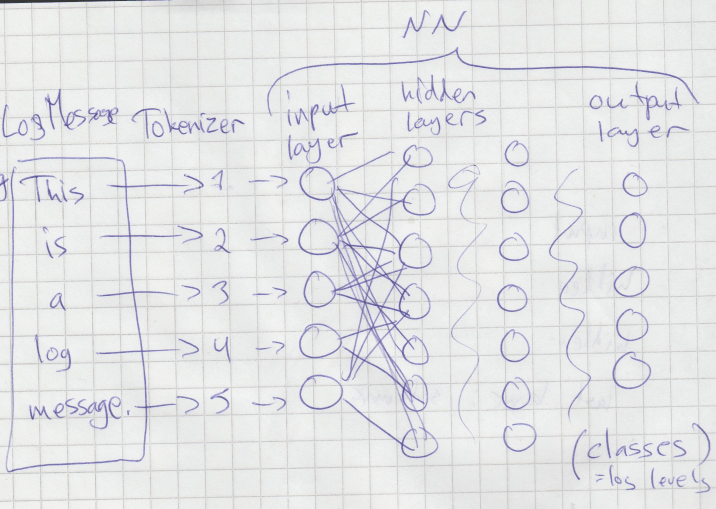
The model
The inputs ready in right format, the model has to be defined. Jeff Heaton’s course on neural networks helped tons, this is the part I used to start with. There are many parameters to tune with the models. Essentially the picture I drew above is somewhat accurate. There are 2 hidden layers, but many more nodes: 10 input nodes in the input layer to start with.
Another article from towardsdatascience.com gave insights on how to choose neural network parameters, but there is a lot room for experiment, and I can’t wait to get my hands dirty 🙂
Test run
If you want to try this at home, you have to provide with journactl generated json logs, process them with the mighty Parser Panda, and run the log classifier model code. Training data had 12529 samples with 50 epochs. Took about a minute to run.
Accuracy score was calculated against the training data itself, and ~80% is really not that good, but this is the first working version, and a milestone in our project!