
Once a prototype is ready, it’s going to break as soon as you move it. And you accidentally delete all your data while investigating what went wrong. This is in essence what happened yesterday. At this point it feels good to say: “No worries, I have backups! Gimme a minute”. Well, more like an hour… The drama can only get better with: “It’s a systemd bug!”.
Introduction
I had finished coding functionality that saves the ML-model along with parameters to document testing. We met with Joni on discord, and went through the steps needed to construct a model on his computer as well:
- Generate JSON formatted logs with journalctl.
- Run Parser-Panda to construct a demo dataset.
- Run lokari-v0.1 to construct a model and save it.
On step 3, we had an error: the tokenizer function complained about data format being wrong. We stared at the code and the data intently for more than an hour and ran some debugging tests. No solution.
Workaround
The code was working on my machine, so finally how we got it to work on Joni’s machine, was to use the same dataset I had on my computer, which was working after all. The code was working on Joni’s machine as expected, and he could do things with it now. Few clues so far: there was something wrong with the dataset, something that was not in string format, but we couldn’t find where it exactly was.
Offhand rm -rf
My workspace got really cluttered while debugging, so I decided to just remove the repository on my local machine and reclone it. Fast and easy. Except that I had all the log data in that directory: 2G of logs gone in an instant.
Backups to the rescue
Don’t panic. Not my style. The data was gathered there from different sources, but I didn’t want to go through the process. So where did I put that data? On my ElasticSearch server of course.
I decided anyway to generate new logs on the machines, and included my laptops logs with it. More logs! More data! Guess what happened?
The error manifested itself again
This was actually a really good thing. I was quite sure the problem was in the dataset, and I looked into it once more. And finally found something:
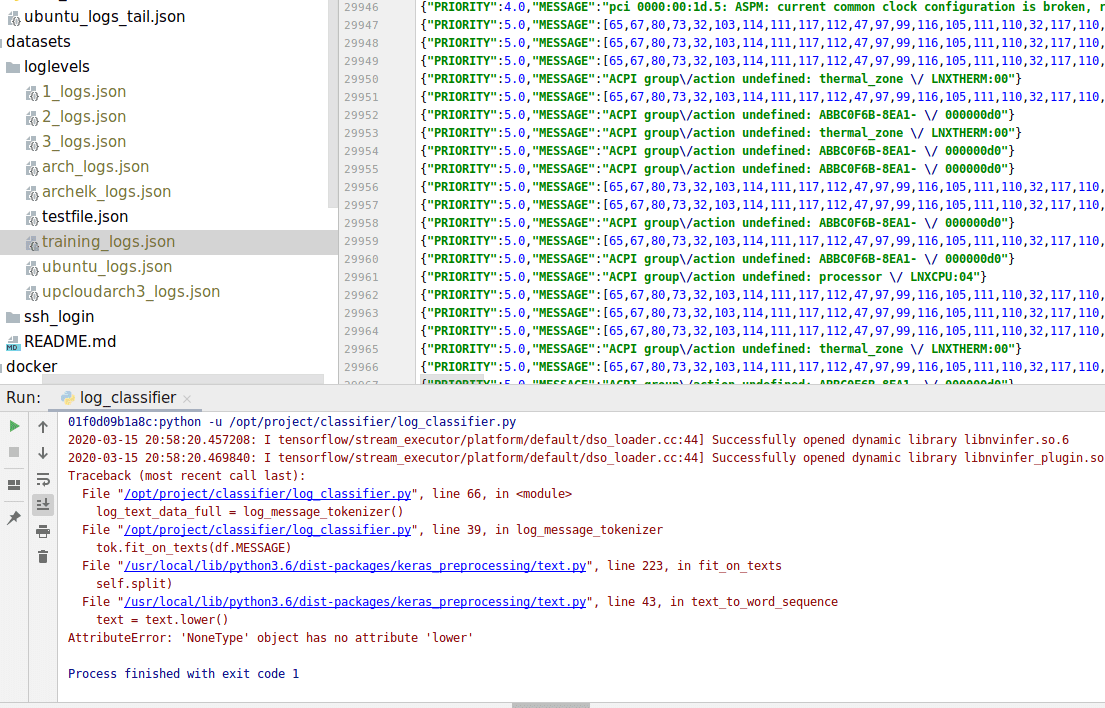
There is the reason: instead of a nice string, there is a list structure on the “Message” -part. Joni confirmed this, as he found similar entries from his dataset.
That data looks suspiciously ASCII-like, which it indeed was. The message actually reads:
ACPI group/action undefined: ABBC0F6B-8EA1-11SITTTTTQ0
Joni had a similar one, a list of ASCII codes, which decoded into:
[31m[23:35:21.078083 WARNING][0m zeitgeist-daemon.vala:454: The connection is closed
Culprit: journalctl
I looked into the data generated by journalctl, and indeed, the data was in list format already in that stage. But the normal journalctl view decodes it correctly. So something happens in the json conversion process, and the result is that the log message is not decoded into text correctly. Intended? Hope not.
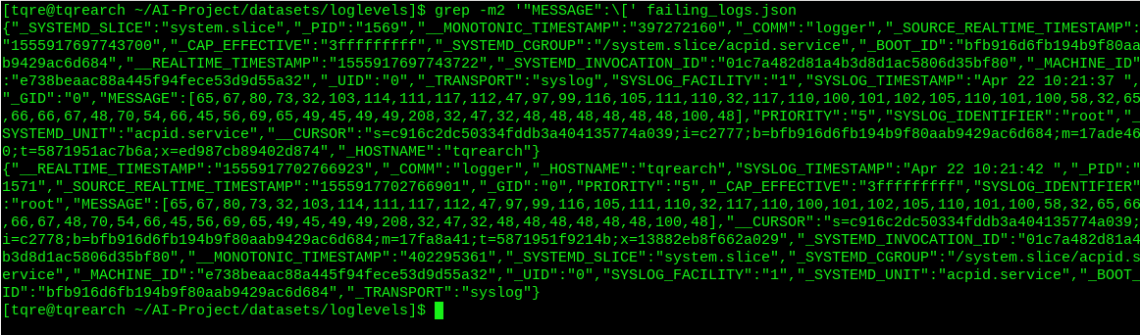
The following commands confirm this: So I know this happens on log level 5: get all level 5 logs from my laptop:
$ sudo journalctl -o json -p 5..5 > failing_logs.json
Then grep the 2 first occurrences, where the message body starts with a ‘[‘.
$ grep -m2 '"MESSAGE":\[' failing_logs.json
Solutions
I gather we have 2 ways to deal with this: implement an ASCII decoder to Parser Panda to work around this bug, or report the bug in journalctl upstream and wait for it to be fixed.
We don’t want to stop working the prototype while waiting the bug to be fixed, so I’m going to work on an ASCII decoder first, then file the bug report.
