The topic and the picture tell the task at hand. Here’s where we are at:
Basic functionality
The program we are making is going to be hooked into a log file, and new appearing logs are fed to a pre-trained model, which knows how a normal log file line looks like.
…new appearing logs are fed…
The first part was solved in no time: python has ‘generators’, which allow for kind of monitoring loops:
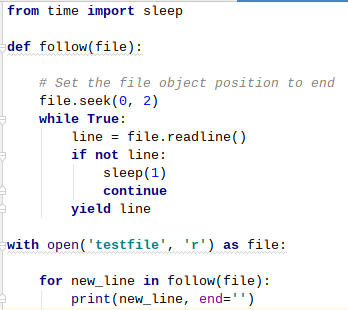
The key here is the ‘yield’ keyword, which actually creates the generator. The while-loop in the ‘follow’ function reads lines from a file, and sleeps for a second if no new lines are to be found. Every time a new line is found, the function ‘yields’ the line, and the last 2 lines of the code print it out. This functionality enables use of infinite loops in functions, and has a plethora of possibilities, including data pipelining…
Basics: https://realpython.com/introduction-to-python-generators/
A very detailed presentation about the possibilities: https://www.dabeaz.com/generators/
…a pre-trained model which knows what a normal log line looks like
This is the main problem. We have restricted it to Apache web server logs, and the more we are looking into it, the more it starts to look like that a general system log anomaly detector needs a lot more time and expertise than we have available.
How to build it?
Here is a graphical presentation of the general idea: the flowchart is work in progress. I’ll try to explain it later once I’m more familiar with the concepts employed here…
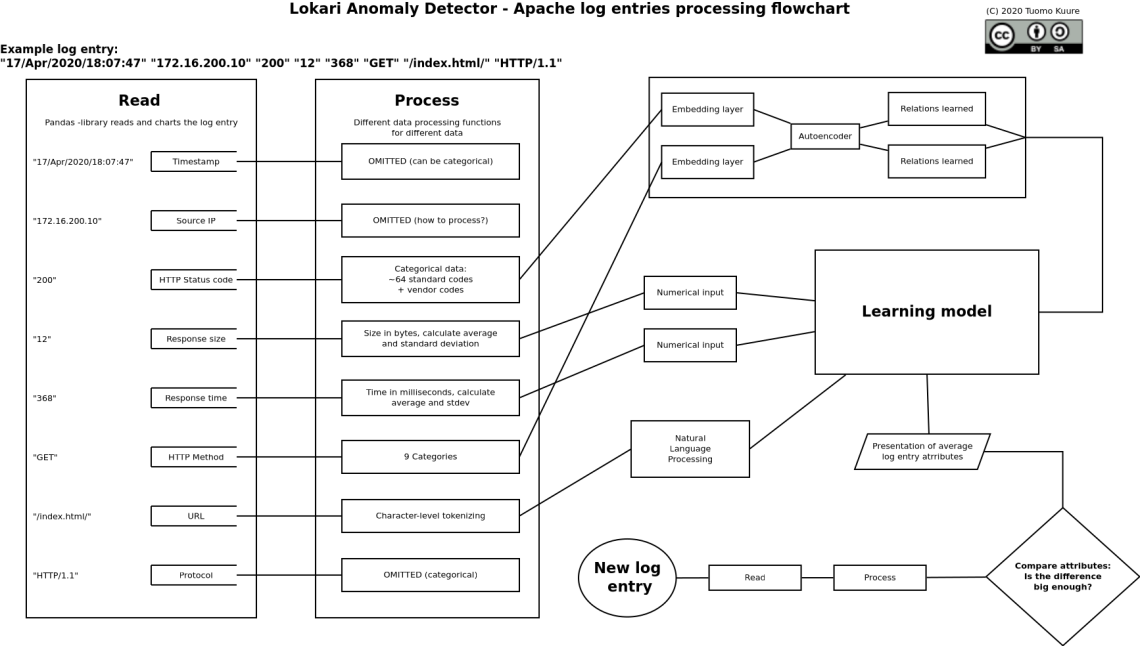
How to improve this? I’m going to print it and grab a pencil 😉
